






Метатег robots и заголовок X-Robots-Tag: руководство по управлению индексированием
Любой сайт — сложная экосистема, где важно управлять видимостью контента в поисковых системах. Иногда нужно скрыть от поисковых роботов технические страницы, скрыть дубли, а в некоторых случаях, наоборот, помочь поисковикам правильно обрабатывать ссылки.
Метатег robots и заголовок X-Robots-Tag — это ключевые инструменты для управления индексацией вашего сайта. Они позволяют точно настроить, какие страницы поисковые системы должны показывать в результатах, а какие — скрыть. При правильном использовании они помогают улучшить видимость сайта, а вот ошибки могут привести к тому, что важные страницы просто исчезнут из поиска. Например, если на важной странице стоит метатег noindex, поисковики не будут её индексировать, и она не появится в результатах поиска.
В этой статье объясним, как правильно использовать эти директивы, когда выбрать meta robots, а когда X-Robots-Tag, и какие ошибки могут отбросить вас в поисковой выдаче.
Что такое метатег robots и как он работает
Это инструкция, которая сообщает поисковикам, как обрабатывать страницу. Он размещается в
и говорит «вот этот контент смотри, а этот нет».
Как это выглядит:

В этом случае поисковики не добавляют страницу в индекс и не передают ссылочный вес через ссылки на ней.
Как поисковики обрабатывают meta robots
Когда бот заходит на страницу, он проверяет метатег robots в
в HTML-коде страницы. Если стоит noindex, страница не попадет в поисковик. Если nofollow, то ссылки на странице не передают вес и могут не сканироваться.
Есть нюансы:
- Google может показывать страницу, если на неё ссылаются другие сайты.
- Яндекс исключает страницу из выдачи, если стоит noindex.
Метатег robots нужен, чтобы:
- скрыть страницу от поиска, но оставить её для пользователей.
- запретить передачу ссылочного веса (с помощью nofollow).
- исключить дублирующий контент.
Для картинок, PDF и других файлов метатег не работает. Для них используется X-Robots-Tag.
Как управлять индексацией страницы через метатег robots
С его помощью вы можете разрешить или запретить сканирование страницы, индексацию контента и даже передачу ссылочного веса. Разберём основные из них в таблице:
|
Директива |
Что делает |
Когда применять |
Пример кода |
|
index, follow |
Разрешает индексацию страницы и переход по ссылкам. |
Используется для служебных страниц, дублей или черновиков. |
|
|
noindex, follow |
Запрещает индексацию, но позволяет боту переходить по ссылкам. |
Если страница не должна быть в поиске, но ссылки на ней важны для SEO. |
|
|
noindex, nofollow |
Полный запрет: страницу не показывают в поиске, а ссылки игнорируют. |
Полезно для рекламных или непроверенных ссылок. |
|
|
none |
То же, что и noindex, nofollow. |
Если хотите записать директиву короче. |
|
|
nofollow |
Разрешает индексацию, но запрещает передавать ссылочный вес. |
Если на странице есть ссылки, которым не стоит передавать значимость. |
Чтобы узнать, какие правила индексации установлены для страницы, можно воспользоваться простым способом проверки прямо в браузере. Для этого откройте нужную страницу, кликните правой кнопкой мыши в любом пустом месте и выберите пункт «Просмотреть код страницы» или аналогичный вариант в вашем браузере.
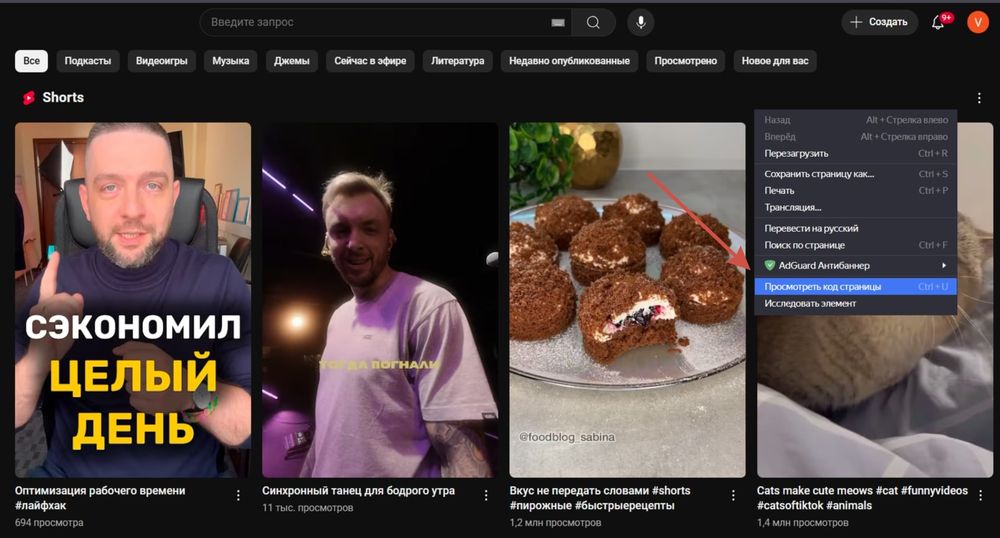
Появится вот такое окошко:
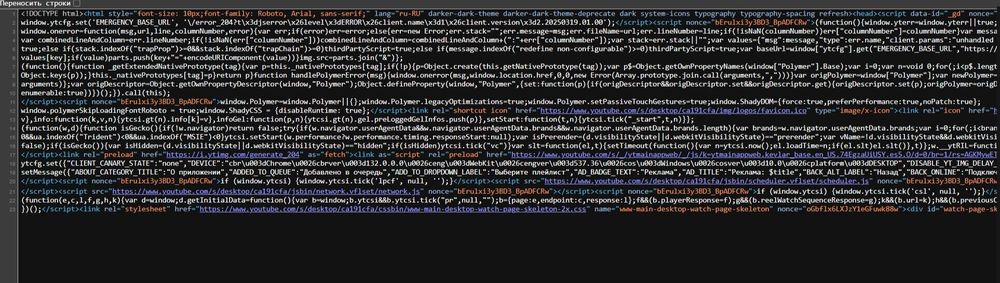
В открывшейся вкладке с HTML-кодом воспользуйтесь поиском по странице, нажав сочетание клавиш Ctrl+F (или Cmd+F для Mac). В строке поиска введите запрос
В случае, когда метатег robots отсутствует в коде страницы, поисковые системы по умолчанию считают, что страницу можно индексировать (index), а ссылки на ней учитывать (follow). Это стандартное поведение для всех веб-страниц, не имеющих специальных ограничений.
Для более удобной проверки рекомендуется использовать SEO-сканеры типа Screaming Frog. Они позволяют массово анализировать метатеги и выявлять потенциальные проблемы с индексацией.
Как правильно использовать метатег robots и не навредить своему сайту
Метатег robots — это точный хирургический инструмент в руках вебмастера. Одно неверное движение — и важные страницы могут исчезнуть из поиска, а ценный трафик испарится. Давайте разберёмся, как им пользоваться без риска.
Где должен находиться метатег
Это не просто формальность — размещение в
документа критически важно. Если вы случайно вставите его в
, поисковые роботы проигнорируют ваши инструкции. Это как поставить дорожный знак за забором — никто его не увидит.
Правильный вариант:

Неправильный вариант:

Поисковые роботы не читают метатеги в
, поэтому такой код не сработает.
Если на странице стоит noindex, поисковик исключает её из индекса. Однако Google и Яндекс ведут себя по-разному:
- Google сначала удаляет страницу из индекса, но если на неё ведут ссылки, может продолжать показывать её в результатах поиска.
- Яндекс сразу исключает страницу из поиска, если она помечена noindex.
Пример ошибки: если на важной категории поставили noindex, Яндекс исключит её из выдачи, и весь раздел перестанет получать трафик.
Можно ли закрыть страницу от индексации через robots.txt
Нет. Robots.txt не запрещает индексацию, а лишь ограничивает доступ к файлу. Если на страницу ведут ссылки, поисковик все равно может ее проиндексировать.
Неправильный способ:
User-Agent: *
Disallow: /private-page/
Так бот не сможет зайти на страницу, но если она уже в индексе, она там останется.
Правильный вариант — использовать meta name="robots" content="noindex".
Как настроить X-Robots-Tag
Запретить индексацию страницы можно разными способами, но не все методы работают одинаково. Разберёмся, когда и что использовать.
Как запретить индексацию всех PDF на сайте
Если файлы не должны появляться в выдаче, X-Robots-Tag можно настроить так, чтобы поисковики их не индексировали.
Обычно это настраивают разработчики или техподдержка хостинга. Важно поставить задачу правильно:
«Закрыть от индексации все PDF-документы с помощью X-Robots-Tag, чтобы они не появлялись в Google и Яндексе».
Когда использовать X-Robots-Tag, а когда meta robots
|
Задача |
Что использовать |
|
Закрыть HTML-страницу |
Meta robots () |
|
Закрыть PDF, видео, изображения |
X-Robots-Tag |
|
Массово запретить индексацию файлов |
X-Robots-Tag |
|
Гибко управлять индексацией страниц |
Meta robots |
Если речь идет о тексте и контенте страниц, проще использовать meta robots. Если нужно скрыть файлы и медиа, X-Robots-Tag — более эффективное решение.
Какие ошибки могут быть при настройке индексации
Настройка meta robots и X-Robots-Tag кажется простой, но ошибки могут привести к потерям в поисковом трафике. Страницы могут пропасть из выдачи, ссылки теряют вес, а запреты не всегда работают как нужно.
Запрет в robots.txt вместо noindex. Часто пытаются закрыть страницу от индексации через robots.txt. Этот файл блокирует доступ бота, но не гарантирует, что страницу не добавят в индекс, если на неё есть ссылки.
❌ User-Agent: *
Disallow: /private-page/
✅
Если нужно закрыть не HTML-страницу, а, например, PDF-файл, используйте X-Robots-Tag.
Важно: Если в robots.txt стоит Disallow, метатег noindex не сработает, потому что поисковик не сможет прочитать страницу. В этом случае используйте X-Robots-Tag или инструмент «Удаление контента» в Google Search Console.
Использование noindex, nofollow на важных страницах. Иногда по ошибке добавляют noindex, nofollow на страницы, которые должны быть в поиске — например, каталоги или карточки товаров. Это приводит к их исчезновению из индекса.
Ваша задача — не использовать эти метатеги и на всякий случай анализировать сайт в Google Search Console.
Noindex для страниц, на которые ведут внешние ссылки. Google может оставить страницу в индексе, даже если на ней стоит noindex, если на неё ведут ссылки с других сайтов. Как исправить:
- Если страницу нужно полностью удалить из индекса, используют инструмент «Удаление контента» в Google Search Console.
- Если noindex не срабатывает, дополнительно закрывают страницу через X-Robots-Tag.
Отсутствие проверки X-Robots-Tag. Если заголовок не настроен на сервере, он просто не будет работать, а файлы все равно попадут в поиск.
Как избежать:
- Проверить заголовки через инструменты анализа HTTP-запросов.
- Следить за отчетами индексации в Google Search Console.
Резюмируем
Правильная настройка индексации — залог эффективного SEO. Ошибки могут привести к потере трафика и ссылочного веса. Чтобы избежать проблем:
- Meta robots используем для HTML-страниц.
- X-Robots-Tag применяем для файлов, изображений и видео.
- Не блокируем страницы в robots.txt, если используем noindex — иначе поисковик не увидит запрет.
- Следим за внешними ссылками, так как Google может оставить страницу в индексе, даже если стоит noindex.
- Проверяем индексацию в Google Search Console, чтобы избежать случайного выпадения важных страниц.
Правильно настроенная индексация помогает контролировать, какие страницы и файлы видит поисковик, и минимизирует риски с SEO.

Наш блог c полезными советами
 28.05.2026
Почему сайт не приносит заявки и как найти ошибки в конверсии
28.05.2026
Почему сайт не приносит заявки и как найти ошибки в конверсии
 28.05.2026
Ahrefs или Semrush: какой инструмент выбрать для SEO
28.05.2026
Ahrefs или Semrush: какой инструмент выбрать для SEO
 28.05.2026
AI-агенты в маркетинге: что это и как они автоматизируют рутину
28.05.2026
AI-агенты в маркетинге: что это и как они автоматизируют рутину
 27.05.2026
ИИ для SEO: как использовать нейросети в SEO-работе
27.05.2026
ИИ для SEO: как использовать нейросети в SEO-работе
 26.05.2026
Core Web Vitals 2026: актуальные метрики и как их улучшить
26.05.2026
Core Web Vitals 2026: актуальные метрики и как их улучшить
 25.05.2026
Как писать SEO-контент под нейросетевую выдачу: структура, формат, подача
25.05.2026
Как писать SEO-контент под нейросетевую выдачу: структура, формат, подача